Öffentlich zugängliche Rechtsprechung für Legal Tech
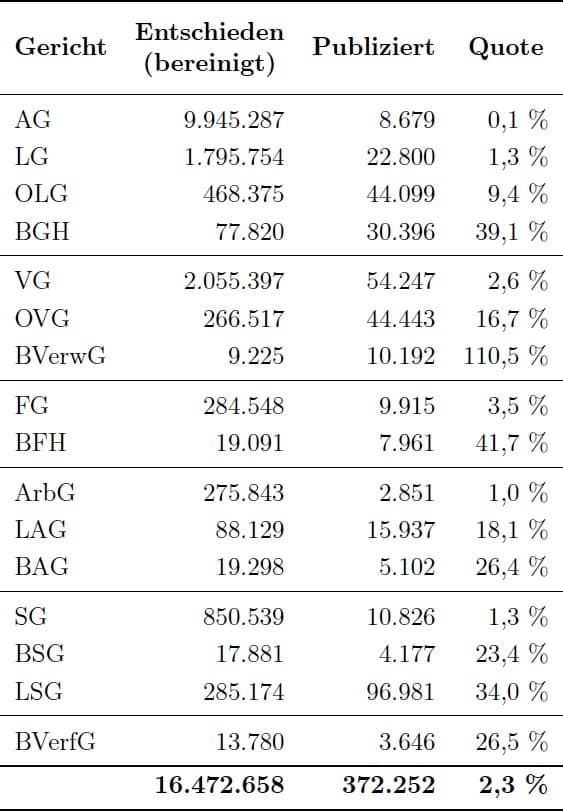
Wenn wir von einer künstlichen Intelligenz (KI) wissen möchten, welches Tier ein Bild zeigt, muss sie zuvor auf Millionen Tierbildern trainiert worden sein. Wenn wir mit einer KI diskutieren möchten, benötigt die KI noch viel mehr Trainingsdaten. IBM’s Project Debater beispielsweise wurde auf 400 Millionen Zeitungsartikeln trainiert. ChatGPT, der Texte übersetzen, zusammenfassen und erzeugen kann (und bei der Erstellung dieses Beitrags mitgeholfen hat), wurde auf mehreren Terabyte Text aus unterschiedlichsten Quellen (Common Crawl, Wikipedia, …) … Mehr





